- 您现在的位置:买卖IC网 > PDF目录69314 > R5F5630ACDFB 32-BIT, FLASH, 100 MHz, MICROCONTROLLER, PQFP144 PDF资料下载
参数资料
| 型号: | R5F5630ACDFB |
| 元件分类: | 微控制器/微处理器 |
| 英文描述: | 32-BIT, FLASH, 100 MHz, MICROCONTROLLER, PQFP144 |
| 封装: | 20 X 20 MM, 0.50 MM PITCH, PLASTIC, LQFP-144 |
| 文件页数: | 45/337页 |
| 文件大小: | 14635K |
| 代理商: | R5F5630ACDFB |
第1页第2页第3页第4页第5页第6页第7页第8页第9页第10页第11页第12页第13页第14页第15页第16页第17页第18页第19页第20页第21页第22页第23页第24页第25页第26页第27页第28页第29页第30页第31页第32页第33页第34页第35页第36页第37页第38页第39页第40页第41页第42页第43页第44页当前第45页第46页第47页第48页第49页第50页第51页第52页第53页第54页第55页第56页第57页第58页第59页第60页第61页第62页第63页第64页第65页第66页第67页第68页第69页第70页第71页第72页第73页第74页第75页第76页第77页第78页第79页第80页第81页第82页第83页第84页第85页第86页第87页第88页第89页第90页第91页第92页第93页第94页第95页第96页第97页第98页第99页第100页第101页第102页第103页第104页第105页第106页第107页第108页第109页第110页第111页第112页第113页第114页第115页第116页第117页第118页第119页第120页第121页第122页第123页第124页第125页第126页第127页第128页第129页第130页第131页第132页第133页第134页第135页第136页第137页第138页第139页第140页第141页第142页第143页第144页第145页第146页第147页第148页第149页第150页第151页第152页第153页第154页第155页第156页第157页第158页第159页第160页第161页第162页第163页第164页第165页第166页第167页第168页第169页第170页第171页第172页第173页第174页第175页第176页第177页第178页第179页第180页第181页第182页第183页第184页第185页第186页第187页第188页第189页第190页第191页第192页第193页第194页第195页第196页第197页第198页第199页第200页第201页第202页第203页第204页第205页第206页第207页第208页第209页第210页第211页第212页第213页第214页第215页第216页第217页第218页第219页第220页第221页第222页第223页第224页第225页第226页第227页第228页第229页第230页第231页第232页第233页第234页第235页第236页第237页第238页第239页第240页第241页第242页第243页第244页第245页第246页第247页第248页第249页第250页第251页第252页第253页第254页第255页第256页第257页第258页第259页第260页第261页第262页第263页第264页第265页第266页第267页第268页第269页第270页第271页第272页第273页第274页第275页第276页第277页第278页第279页第280页第281页第282页第283页第284页第285页第286页第287页第288页第289页第290页第291页第292页第293页第294页第295页第296页第297页第298页第299页第300页第301页第302页第303页第304页第305页第306页第307页第308页第309页第310页第311页第312页第313页第314页第315页第316页第317页第318页第319页第320页第321页第322页第323页第324页第325页第326页第327页第328页第329页第330页第331页第332页第333页第334页第335页第336页第337页
R01UH0040EJ0100 Rev.1.00
Page 139 of 1657
Sep 8, 2011
RX630 Group
2. CPU
(d)
When the load data is not used by the subsequent instruction
When the load data is not used by the subsequent instruction, the subsequent operations are in fact executed earlier and
the operation processing ends (out-of-order completion).
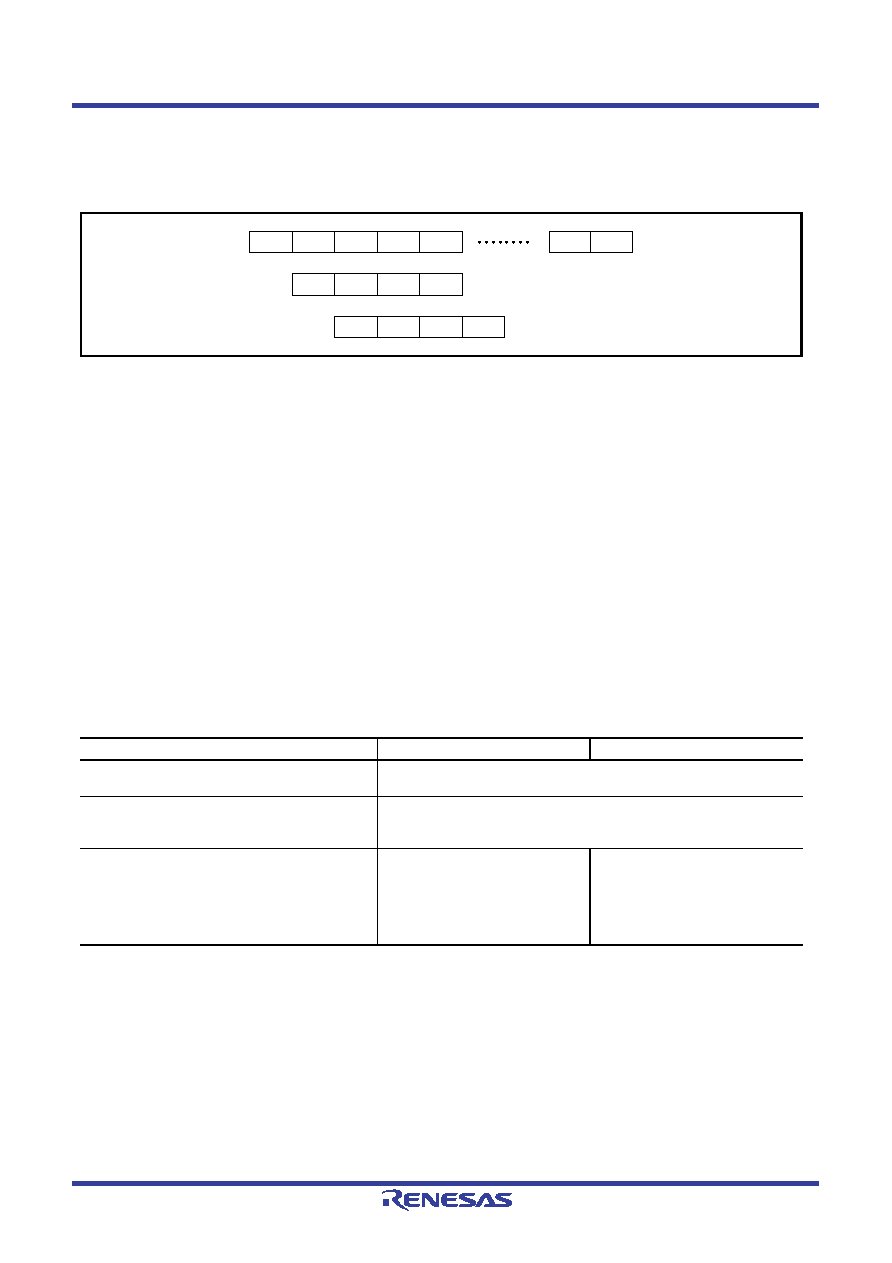
Figure 2.27
When Load Data is not Used by the Subsequent Instruction
2.8.3
Calculation of the Instruction Processing Time
Though the instruction processing time of the CPU varies according to the pipeline processing, the approximate time can
be calculated in the following methods.
Count the number of cycles (see Table 2.13 and Table 2.14)
When the load data is used by the subsequent instruction, the number of cycles described as “latency” is counted as
the number of cycles for the memory load instruction. For the cycles other than the memory load instruction, the
number of cycles described as “throughput” is counted.
If the instruction fetch stall is generated, the number of cycles increments.
Depending on the system configuration, multiple cycles are required for the memory access.
2.8.4
Numbers of Cycles for Response to Interrupts
Table 2.15 lists numbers of cycles taken by processing for response to interrupts.
Times calculated from the values in Table 2.15 will be applicable when access to memory from the CPU is processed
with no waiting. The on-chip RAM and ROM in products of the RX630 Groups allow such access. Numbers of cycles
for response to interrupts can be minimized by placing program code (and vectors) in on-chip ROM and the stack in on-
chip RAM. Furthermore, place the addresses where the exception handling routine start on eight-byte boundaries.
For information on the number of cycles from notification to acceptance of the interrupt request, indicated by N in the
table above, see Table 2.13, Instructions that are Converted into a Single Micro-Operation, and Table 2.14,
The timing of interrupt acceptance depends on the state of the pipelines. For more information on this, see section
Table 2.15
Numbers of Cycles for Response to Interrupts
Type of Interrupt Request/Details of Processing
Fast Interrupt
Other Interrupts
ICU
Judgment of priority order
2 cycles
CPU
Number of cycles from notification to acceptance of
the interrupt request
N cycles
(varies with the instruction being executed at the time the interrupt was
received)
CPU Pre-processing by hardware
Saving the current PC and PSW values in RAM
(or in control registers in the case of the fast interrupt)
Reading of the vector
Branching to the start of the exception handling
routine
4 cycles
6 cycles
IF
D
E
MOV [R1], R2
IF
D
E
M
WB
IF
D
E
WB
ADD R4, R5
SUB R6, R7
(mop) load
(mop) add
(mop) sub
相关PDF资料 |
PDF描述 |
|---|---|
| R5F5630BDDFB | 32-BIT, FLASH, 100 MHz, MICROCONTROLLER, PQFP144 |
| R5F5630DCDFC | 32-BIT, FLASH, 100 MHz, MICROCONTROLLER, PQFP176 |
| R5F61634N50FPV | 32-BIT, FLASH, 50 MHz, MICROCONTROLLER, PQFP120 |
| R5F61642N50FPV | 32-BIT, FLASH, 50 MHz, MICROCONTROLLER, PQFP144 |
| R5F61648N50FPV | 32-BIT, FLASH, 50 MHz, MICROCONTROLLER, PQFP144 |
相关代理商/技术参数 |
参数描述 |
|---|---|
| R5F5630ACDFC | 制造商:RENESAS 制造商全称:Renesas Technology Corp 功能描述:Renesas MCUs |
| R5F5630ACDFP | 制造商:RENESAS 制造商全称:Renesas Technology Corp 功能描述:Renesas MCUs |
| R5F5630ACDFP#V0 | 制造商:Renesas Electronics Corporation 功能描述:MCU2 RX600 RX630-090 F630 - Trays |
| R5F5630ACDLC | 制造商:RENESAS 制造商全称:Renesas Technology Corp 功能描述:Renesas MCUs |
| R5F5630ACDLC#U0 | 制造商:Renesas Electronics Corporation 功能描述:RX630 768KB/96KB LGA177 100MHZ - Trays 制造商:Renesas Electronics Corporation 功能描述:IC MCU 32BIT 768KB FLASH 177LGA |
发布紧急采购,3分钟左右您将得到回复。